
2009-03-24 20:33:42
Merge History, DAGs and Darcs
One of the popular complaints about CVS and Subversion (before 1.5) was the lack of merge history. In a nutshell, merge history is remembering what has been merged and taking that information into account on future merges.
In a bucket?
In something bigger than a nutshell, merge history is a lot more complicated.
Unless you completely eschew branching, you are going to frequently find yourself wanting to take some changes you made in one place and re-apply them somewhere else. When you do this, you want your version control to make it painless. Without merge history, it is very difficult to make change migration painless, since the tool will try to do things that have already been done.
A common example is the case of two branches that occasionally want to merge changes from one side to the other.
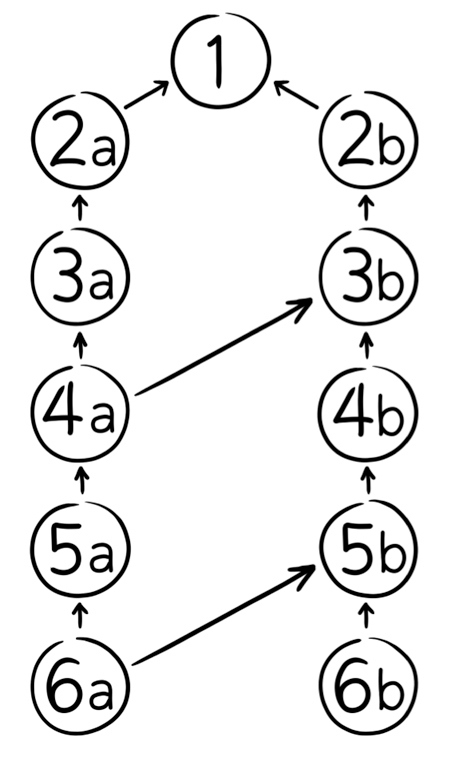
Here I have two branches of development. On two occasions, somebody merged changes from branch (b) over to branch (a). (Arrows go from a changeset to its parents.)
Without merge history, this can be a real pain. When branch (a) tries to grab changes from changeset 5b, CVS doesn't remember that 3b and 2b have already been applied. So it attempts to apply them a second time, resulting in conflicts, pain and frustration and a general fear of branching.
One of the coolest things about DAG-based version control tools is that the DAG is an expression of merge history. We interpret arrows in the DAG to mean "'I've got this".
So, when it comes time to do merge from 5b over to the (a) branch, we can use information in the DAG to know that 3b and 2b are already done. I'm not saying the algorithm to use this information properly is trivial, but there are multiple implementations, and they work pretty well in practice.
For example, Git has a repuation for excellent and painless branching and merging, and the DAG is the main reason why.
Cherrypicking
But a DAG is just one implementation of merge history, and it is definitely not perfect.
An arrow in a verson control DAG goes from child to parent. It tells us that the child contains all of the changes in the parent. And its grandparents. And its great grandparents. And so on.
But what if this isn't true?
Consider the following picture:
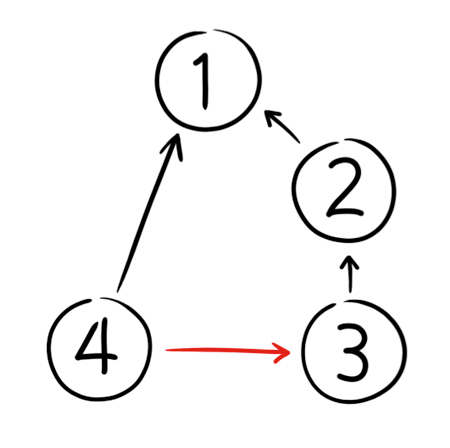
I want to create changeset 4. I want to start at changeset 1, and then I want to apply the changes from changeset 3, but NOT the stuff in changeset 2. This operation is sometimes called "cherrypicking". I don't want to merge all changes from one branch to another. I just want to pluck one changeset (or one part of a changeset) and apply it as a patch to some other place.
How do I represent this in the DAG?
I can't.
- I could draw an arrow from 4 to 3 (shown above in red). This would correctly say that 4 contains the changes in 3, but it would INCORRECTLY claim that 4 contains the changes in 2.
- OR, I could draw no arrow. Effectively, my merge history would simply not record the fact that 4 is really 3 converted to a patch and applied to 1.
In either case, something bad is going to happen next time I merge from one branch to the other:
- If I draw that lying arrow, I will not be given the chance to apply changeset 2, because the merge history believes I already did it.
- If I don't draw any arrow, the tool will expect me to deal with changeset 3, because there is no merge history recording the fact that I already did it.
Neither of these problems is disastrous enough to make the evening news, but still.
DAG-Like Things
It's tempting to think that the problem lies in the way I defined my DAG lines. Perhaps a line should mean "just you, not your parents?" But then I would I need to have a line from every changeset to every one of its ancestors. This would be completely infeasible.
Or perhaps we need two kinds of DAG lines?
- Regular lines are the normal case. They imply recursive inclusion. We'll draw them in black.
- Red lines are for cherrypicking. When a red line points to a changeset, it says, "I've got this, but not its ancestors." Red lines imply shallow inclusion.
But now our DAG is not really a DAG anymore. If we're going to use a DAG, we'd like to be able to use the decades of computer science research about how to deal with them. AFAIK, all the well understood algorithms about DAGs assume there is only one kind of line.
For example, is changeset 3 a leaf? Well, maybe. If you ignore the red lines, then 3 is a leaf. But if red lines count, then 3 is an interior node.
Many CS algorithms become less useful when questions start getting answered with "maybe".
Darcs
So, even though the DAG is a pretty good representation of merge history, it isn't perfect.
Darcs is an attempt to build a better solution to the problem.
Several weeks ago I divided version control tools into two groups:
- Those where the history is a Line.
- Those where the history is a Directed Acyclic Graph (a DAG).
But darcs doesn't really fit in either of these categories. Its model of history is certainly not a Line. But it's not really a DAG either, at least not in the same way as Git and Mercurial.
A darcs changeset records the full merge history at the patch level. Darcs has a nice well-defined algebra of patches which allows it to accomplish some very clever things.
But while I consider the concepts behind Darcs to be fascinating, I also consider them to be raw and unproven in practice. I can't see how the algorithm would scale to big problems. And people who know darcs are always talking about the possibility of the merge algorithm going exponential.
Darcs seems to have a more complete representation for merge history. But that doesn't mean there is any practical algorithm for making use of that information.
For now, I must consider darcs to be in the category of research, not development.
Final Thoughts
Merge history is a very hard problem. Some of the imperfect solutions have found their way into common usage and proven themselves to be quite practical. But there is a lot more that could be done.
Need a thesis topic for your PhD in computer science? Go find a better solution to the merge history problem.