
2010-08-14 13:56:34
Video of my presentation from OSCON 2010
 For those who are interested, we've posted the video of
my presentation at OSCON on YouTube.
For those who are interested, we've posted the video of
my presentation at OSCON on YouTube.
I had a few problems when displaying my slide deck at the conference. When I'm speaking at an event, I usually like to use whatever equipment is provided. To be assured of compatibility between my MacBook Pro and the projector, I would need to bring like [what seems like] 23 different video adapters. It's easier to just bring my slide deck on a thumb drive.
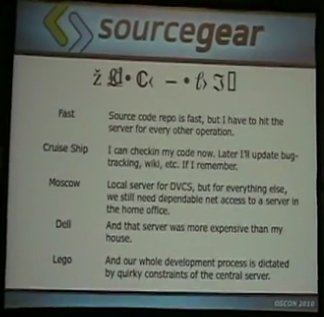
The email from the conference organizers told us there would be "Dell laptops" in the room. I remember thinking how boneheaded it was of them to be running Windows at the Open Source convention, but I complied and brought my slides as a PowerPoint file.
And then I got there and discovered that I was the one being a bonehead for assuming that "Dell laptop" == "Windows + Office". Actually, those Dell laptops were running Linux with OpenOffice.org. Anyway, OO.org imported my .pptx file, but it botched the formatting in some rather unexpected and entertaining ways.
Moving Forward
Since OSCON ended three weeks ago, folks on our team have been taking their summer vacations, but we've still made some good progress:
- After hearing lots of (well deserved) complaints from
people trying to build 64-bit Veracity, we expanded our continuous
integration build farm to do both 32 and 64 bit builds, debug and release,
on all our platforms.
- We had just missed our goal of dogfooding Veracity's
bug-tracking features before OSCON, but after another round of
improvements to the Web UI stuff, now we're using Veracity not just for
source control, but also for project tracking.
- We implemented Mercurial-style version numbers. They're
specific to one instance of a repo, but still kind of handy.
- We started work on letting Veracity run through mainstream
web servers (instead of only using its embedded web server).
- We did lots of bug fixes, including some deep polishing
and testing work on patterns for include/exclude settings.
- I've been working in a private branch, focused mostly on
improving performance:
- Every changeset record has a blob list which is used for
making things like push/pull and incremental indexing efficient. For
changesets which are a DAG merge (more than one parent), we need to
normalize that blob list to ensure that the exact same list is
constructed on each side of the merge. Our previous normalization code
was additive. It walked the DAG back to the lowest common ancestor and
added any blob which wasn't present on both sides. Gradually, this
caused those blob lists to keep getting bigger and bigger, which turned
out to be a nasty performance probem that gets worse as the repo grows.
So, I switched the normalization code to remove any blob which was
present in the blob list of any ancestor. This is a lot harder to
calculate, but it results in a much tighter list.
- The changeset record for a database DAG includes a
delta. When that changeset is a merge, the delta is calculated against
the lowest common ancestor of the two parents. However, when it comes
time to store that delta for later use by the indexing code, it would be
better to calculate an equivalent delta against one of the two parents.
- In a Veracity database, every record has two fields:
recid and rectype. However, some our databases just don't need both of
these fields. For example, recid is really only useful if you plan to
modify records, but the audit DBs are filled with record that never get
modified. Similarly, if a DB only has one record type, we don't need
every single record to have a field reminding us what the name of that
type is. So, I made a bunch of changes to allow a Veracity DB to exclude
one or both of these fields. Eliminating the need to store, retrieve,
index and obey these superfluous fields resulted in a nice perf increase.
- I went through and made dozens of little optimizations in
the indexer. Remember to always use SQLite's prepared statements in
loops. Make sure every blob getting indexed only gets loaded once. Tune
the hash table which represents JSON objects.
- I found and fixed a few GC rooting bugs in our SpiderMonkey
code. BTW, I can't wait until we can upgrade to new
and improved version of the JS engine. I greatly dislike the fact
that SpiderMonkey doesn't have a wider int.
- Unfortunately, some of my changes break compatibility, so
I've been writing a script to migrate all our data. This week I'll merge
with the trunk and we'll do what we call a "repository reboot".
- This firehose of detail is mostly just the ramblings of
yet another blogger who is under the delusion that anybody cares about
the mundane elements of his day. Which reminds me, Thursday morning for
breakfast I had iced coffee with an omelet made of red peppers,
Portobello mushrooms, and provolone. Anyway, on the off chance that
anything here wants to get discussed, meet me on the Veracity
mailing list.
After things settle down just a bit more, we'll be ready to start publishing nightly tarballs.